Messages used during Sync
Let's get rid of the low-level protocol stuff first. There are a few of them as shown in the following diagram.
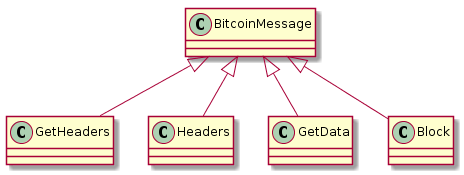
GetHeaders and GetData are the request messages. In response the remote node sends Headers and Blocks.
They simply all derive from the same base class. More interesting is the way they relate to each other.
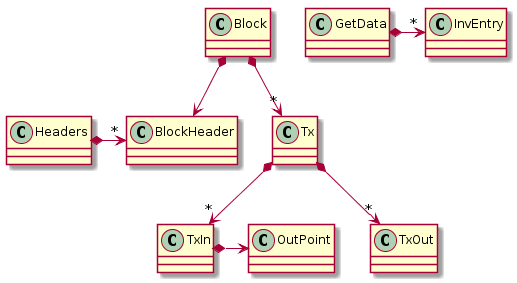
They are a few internal classes introduced here. Each block of the Blockchain contains one or many transactions. Preceding the transactions, we have a block header. We can request only the block headers using the GetHeaders command. Transactions have zero or many inputs and zero or many outputs. An input refers to another transaction by position (a transaction hash and an output index).
The exchange of messages with the remote peer follows this sequence diagram.
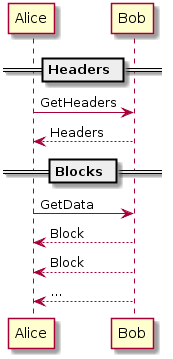
We get several headers at once in a reply to GetHeaders (up to 2000) but we get an individual block message as replies to GetData.
The implementation of these classes isn't very special, the only point worth noting is that blocks and transactions are identified by hashes which are not stored in them. Storing the hash is useless since it can be calculated. The reader takes care of computing the hashes and storing it in the object. For blocks, it is also useful to extract the header in its own class because it is the same object that is returned in the message.
Just three classes have an important role in the sync process.
case class BlockHeader(hash: Hash, version: Int, prevHash: Hash, merkleRoot: Hash, timestamp: Instant, bits: Int, nonce: Int, txCount: Int) extends BitcoinMessage
case class Headers(blockHeaders: List[BlockHeader]) extends BitcoinMessage
case class Block(header: BlockHeader, txs: Array[Tx], payload: ByteString) extends BitcoinMessage
Among them, we are going to work mainly with BlockHeader. txCount has a unique behavior. In the Headers message, it will always be
equal to 0. Moreover it is not part of the hashed data. Because of that, we have to handle this field differently than the others.
Block has redundant field payload which is the original binary payload. It is kept around because blocks are written to disk.
This saves having to serialize the block content when we already have it from the network.
Next: A look at the sync interface
